Designating a partition column
To designate a partition column, do the following:
-
Navigate to the data source page for which you want to AI generate the metadata catalog.
-
Go to the Tables tab and click the link of the specific table you wish to catalog.
-
In the Table Info page, click the Column info tab.
-
From the extreme right click the more options icon corresponding to a column and select the Make partition column option. This option is available only for columns with following data types: int, bigint, timestamp, long, and date.
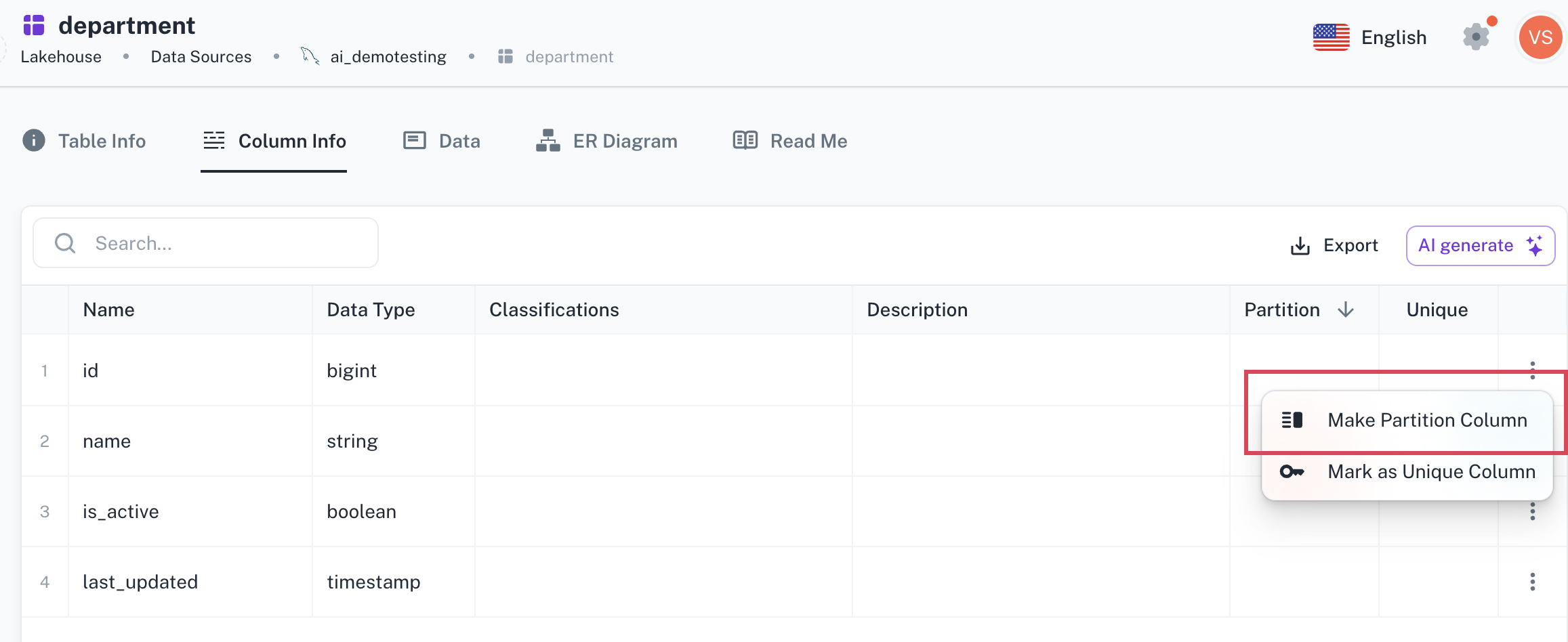
-
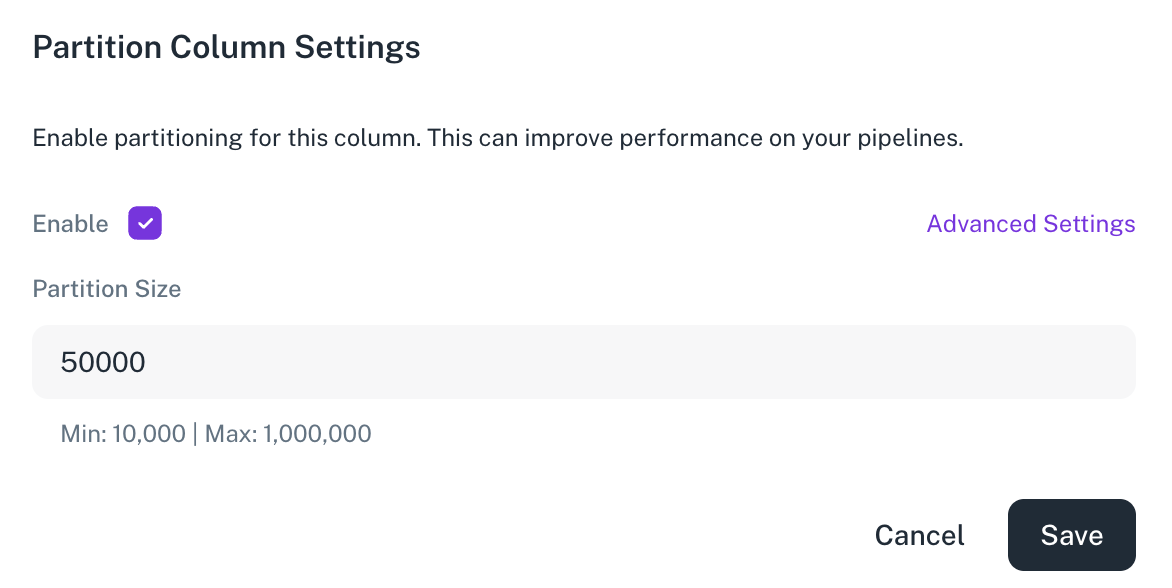
In the Partition Column Settings box, select the Enable checkbox. You can also click Advance Settings and specify the partition size.
The column that is specified as the partition column is ticked in the listed.
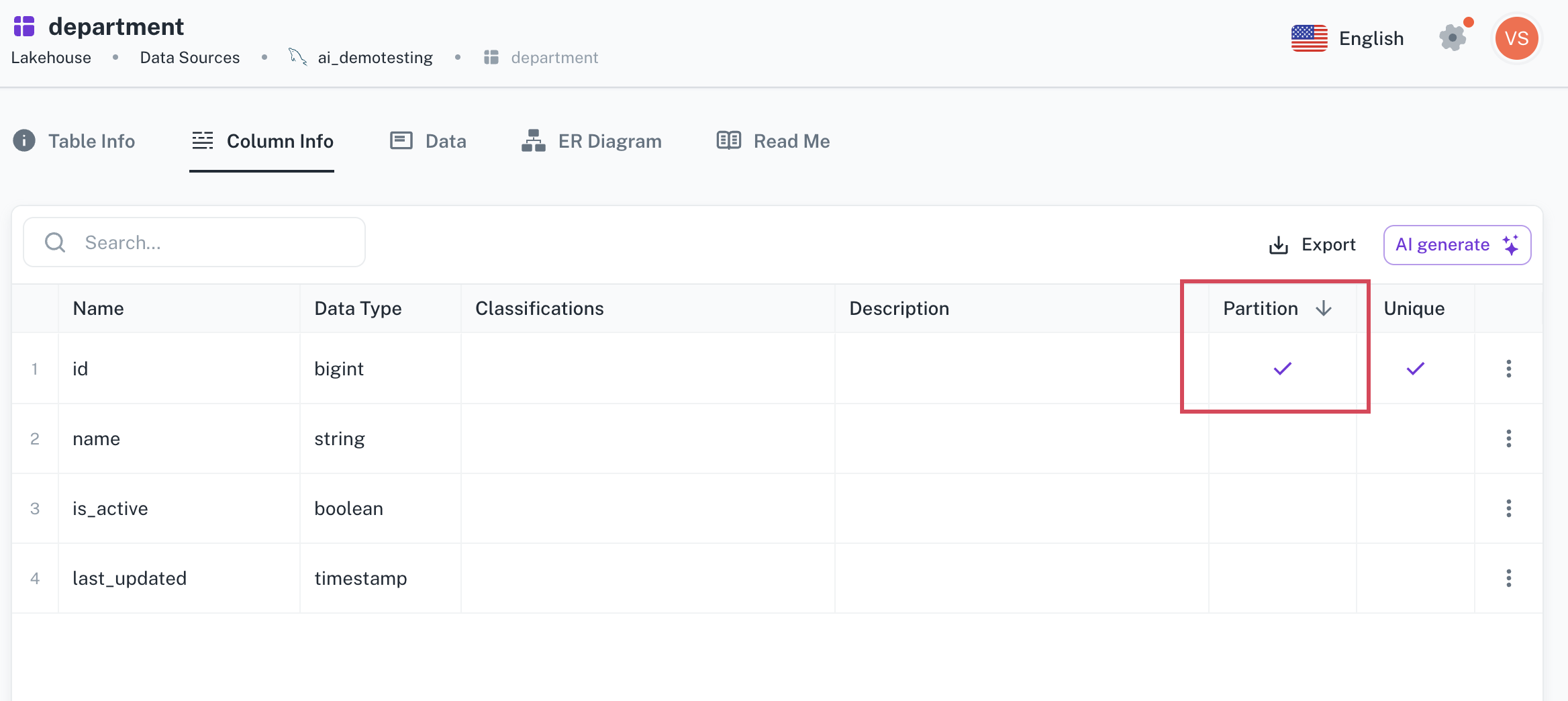
The designated column will be used as the partition column by Apache Spark while processing datasets. Only a single column can be used as a Partition Column. The default partition size is 50K.
infoThis setting is available only for RDBMS data sources.
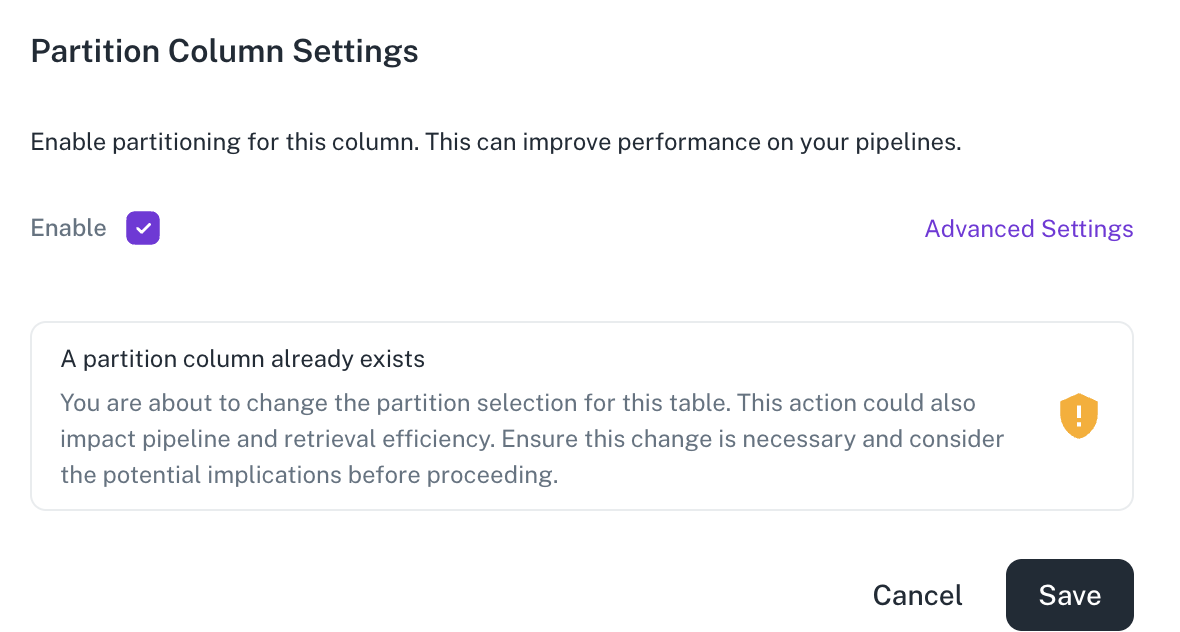
warningIf you attempt to change the partition column, a warning is displayed, since this action can impact the pipeline and retrieval efficiency.